
Made at Intel: Сделано в Intel
И снова о «гениях»
В момент краха Xeon Phi я был от этого уже довольно далеко. Последние годы в Intel (2016–2020) я провел, возглавляя команду VTune. И фокус моего внимания был сильно смещен в сторону uncore. Во-первых, хотелось какого-то разнообразия. Во-вторых, uncore-поляна, в отличие от core, была сильно менее изученной и «затоптанной». В-третьих, становилось понятно, что с увеличением числа ядер в процессоре роль core падает, а uncore – растет. Центром «анкорной» мысли тогда была тусовка под названием IO-intensive workloads group[9]. Я еще в шутку называл ее «клубом любителей DPDK». Кроме самого DPDK, в игре были и другие прилаги – базы данных, Hadoop, Ceph. Но всепроникающая сила Линпака в «Интеле» была такова, что он сумел меня достать и там. Проблемы наша группа обсуждала суровые. Вот есть core, uncore, шина и девайс – и все это работает на разных частотах. Как сопрячь, буферизовать и синхронизировать? А как быть с RDMA? В общем, почти любой доклад на этой группе так или иначе превращался в «плач Ярославны». И если core-тусовка, периодически наступая на грабли, оставалась более или менее на позитиве, то наша лавочка напоминала сборище неисправимых нытиков.
Был там такой «обряд посвящения», стихийно сложившийся и оттого особенно смешной. Бывало, приходил к нам мальчик, только что закончивший Стенфорд, Беркли или другое уважаемое учебное заведение Объединённых Штатов Северной Америки. Первый раз он обычно сидел тихо, внимательно слушая наши стенания. Зато в следующий раз приходил одухотворенный.
– Ребята, я понял, что надо сделать.
– Ну и?
– Надо понизить частоту ядра. Ведь оно все равно по большей части ждет ввода-вывода. И чем меньше оно намолотит тактов в этом процессе, тем лучше, – в этот момент у ветеранов тусовки делались уксусно-кислые лица. Типа «ну вот, еще один юный гений»…
– Все это логично, правильно и было бы хорошо, если б не одно «но», – в тот день была моя очередь «резать правду-матку».
– Какое?
– Знаешь, что сделает с нами маркетинг за недобор флопов на Линпаке? Он утопит нас в пруду. Всех в одном мешке, как котят. Даже не будет разбираться, чья идея была.
– Правда? – голос у паренька заметно дрожал.
– Ага. Добро пожаловать в реальный мир.
На этом разговор закончился, но спустя некоторое время пожилой и уважаемый всеми индус, который председательствовал в группе, сделал мне замечание в личной беседе:
– Зря ты так, Валер. Парнишка прям серьезно расстроился.
– Да ладно, пусть привыкает. Здесь не Стенфорд.
И тут он меня ненавязчиво осадил:
– Ну, ты сам-то вспомни, что сказал, когда первый раз к нам пришел…
Architecture and religion – 3
Главная вера
И все же важнейшей религией компании является сама x86 Instruction Set Architecture[10]. Intel изначально свято придерживался принципа backward compatibility[11] – программы, написанные для предыдущих поколений процессора, работают на следующих без изменений (ну, разве что требуют эмулятора операционки). Без этого нельзя построить никакой экосистемы, ибо ее формирование – процесс, занимающий многие годы. И именно благодаря последовательности Intel x86 ISA стала для компьютерного мира чем-то вроде христианства. Аналогию можно продолжить, сравнив разделение христианства на католическую и православную ветви – Intel и AMD (или наоборот). Но мы этого делать не будем. Однако принцип backward compatibility требует, чтобы любое изменение ISA оставалось в ней навсегда. И, наверно, нам следовало относиться к архитектуре более бережно. Когда я был маленьким, а деревья большими, один умный человек (Ronak Singhal) говорил мне, что тут, дескать, не о чем печалиться. С каждым shrink (переходом на более совершенный процесс изготовления чипов) площадь, необходимая для поддержки legacy[12] инструкций, «сжимается» в два раза. Но вот когда Intel серьезно «застрял» на 10-нм техпроцессе, мои опасения вернулись с удвоенной силой.
Отчасти, впрочем, наши промахи можно объяснить тем, что x86 – «закрытый клуб», в отличие от ARM и тем более RISC–V. Ну, например, собирается ARM «выкатить» новую версию ISA. Он будет согласовывать ее со всеми основными вендорами – Apple, Samsung, Qualcomm и т. д. Поэтому у него куда меньше шансов совершить какую-нибудь глупость. Intel, конечно, тоже советуется с основными партнерами – Microsoft, Google, Amazon. Но основные решения все же принимаются внутри. Мне это почему-то представлялось так. На унылом севере, вдали от людского жилья, стоит темная башня. Лишь на последнем этаже ее горит свет. И там наверху собрались адепты тайного ордена… В случае с «Интел» «орден» имеет вполне конкретное название – ISA CPT. Именно там принимаются самые важные архитектурные решения. На этот митинг вхожи лишь ведущие технические лидеры компании – Fellows, Senior Principal Engineers. Мне трудно всерьез назвать себя одним из адептов (так, скорее, младшим послушником). Но я всегда был юношей любопытным, и время от времени мне удавалось туда пролезть – (восьмым) содокладчиком в какой-нибудь презентации или просто «вольным слушателем». Чаще все же приходилось довольствоваться информацией из вторых-третьих рук. И сегодня я немного расскажу вам о разного рода «ересях», которые зарождались и погибали внутри «Интел».
Гибель «Титаника»
Хотя Itanium нарекли «Титаником» сразу же после анонса архитектуры 4 октября 1999-го, он не был поначалу и вполовину так плох, как его реноме. Архитектура VLIW/EPIC смотрелась необычно по сравнению с CISC и манила новыми возможностями. Мою фантазию будоражили предикатное исполнение, вращающиеся регистры и explicit software pipelining[13]. К тому же IA-64 была in-order[14] архитектурой – можно было точно предсказать, сколько будет обрабатываться один элемент достаточно длинного цикла при условии прогретых кэшей. Для кого как, а для меня эта «иллюзия контроля» почему-то всегда была важна. Тогда я еще плохо представлял себе важность software ecosystem[15] для успеха платформы. Да, понимал, что работа предстоит огромная, но шансы представлялись вполне себе неплохими.
Но все же Itanium, как и «Титаник», видимо, был проклят с самого начала. Дело в том, что против него играли как религия (not invented here[16]!), так и политика. А в средневековом государстве это необоримая сила. «Крестным отцом» Itanium был Mike Fister, тогдашний глава серверного подразделения Intel. И в начале 2000-х между ним и Полом Отеллини развернулась борьба за то, кто станет следующим CEO Intel после Kрейга Баррета. Борьбу эту Captain Itanic[17] проиграл и ушел в CEO в Cadence (который, безусловно, уважаемая компания, но все же не Intel). Также ко дну пошло его детище. А спасать было некому – Отеллини Itanium не жаловал. Уж не знаю, вследствие «разборок» начала 2000-х или по каким-то другим причинам… К тому же обнаружилась масса других проблем.
• Индустрия как-то сразу не поверила в Itanium. Портирование софта шло без особого энтузиазма. А Intel не решился на большую ставку – Itanium enabling strategy[18] всегда оставляла у меня ощущение какой-то недосказанности…
• Возможно, расчет был на x86 compatibility block[19], но именно он стал больным местом Itanium – энергии потреблял больше, чем весь остальной процессор, и грелся, как сволочь. Бинарный транслятор также не выглядел панацеей: преобразование из CISC в VLIW является одним из самых сложных (хотя на «Эльбрусе» как-то работает).
• Насколько увлекательным являлось написание микрокернелов для Itanium на ассемблере – настолько кошмарным было портирование приложений. Компилятор является основным камнем преткновения для архитектуры VLIW/EPIC. Одно из немногих исключений, которое я знаю, – опять же «Эльбрус». Но для того чтобы довести его компилятор до ума, потребовалось порядка 20 лет. «Интел» столько ждать не захотел…
• Ну и последнее – Itanium всегда выпускался с отставанием на шаг по техпроцессу от x86. И в этом трудно не усмотреть наличие «доброй» политической воли.
IA-64 влачила жалкое существование до начала 20-х. И лишь в феврале 2019-го Linus Torvalds сказал: «It’s dead, Jim[20]». Но можно было спокойно сделать это и на 10 лет раньше. И все же у меня осталось от Itanium ощущение «неспетой песни». Да, я не люблю VLIW (я тоже религиозен) и мне кажется, что рано или поздно мы бы все равно «уперлись» в его ограничения. Но все же стоило пытаться по-честному пройти этот путь…
X-Files
Архитектура StrongArm (а впоследствии XScale) – еще одно наследие, полученное Intel от DEC. Было тогда в компании подразделение Intel Communication Group[21]. Ваяло контроллеры для IO и сетевых устройств. И там неприхотливый и экономичный ARM пришелся весьма ко двору. Но именно в этот момент наступила эпоха handheld-девайсов (наладонников, как их тогда называли) – предтечи современных смартфонов. Intel попробовал – и оно как-то сразу полетело. BlackBerry, Dell, Compaq, Toshiba, Palm, Amazon Kindle – вот далеко не полный список компаний, начавших производство продуктов на базе XScale. Воодушевившись, в 2004-м Intel выпустил SIMD-расширение ISA под названием Wireless MMX. И в отделе IPP (в котором я пребывал с 2002-го по 2005-й) закипела работа по оптимизации библиотек.
И вдруг… как гром среди ясного неба в 2006-м грянула новость – Intel продает XScale бизнес Marvell за жалкие 600 миллионов долларов. Бросьте в меня камень, но я по чисто бизнесовым причинам считаю это одной из самых больших ошибок компании. Недостатки этого решения более чем очевидны.
• Мы в очередной раз «прокинули» своих клиентов (впрочем, не в первый и не в последний).
• Вместе с XScale ушла команда, наработавшая уникальную экспертизу в области мобильных устройств. И потом ее ой как не хватило…
• XScale был «входным билетиком» в мобильную экосистему. А кому как не Intel понимать ее значение. И беспечно выбросив его, мы сами захлопнули дверь перед собственным носом.
• Именно в тот момент, недооценив потенциал рынка смартфонов и планшетов, Intel обрек на неудачу свои дальнейшие (дорогостоящие) попытки стать там существенным игроком. (Способности Intel предсказывать индустриальные тренды я еще коснусь в одной из следующих глав.)
Объяснение у меня только одно, чисто религиозного характера. XScale был ARM-ом. Not made at Intel. Уже зрел в недрах компании Atom – low-power[22] процессор с «православным» набором команд. И Intel принял решение избавиться от «чужеродного» продукта (мне до сих пор представляется правильной стратегией на тот момент – тащить одновременно две линейки). Я сейчас выскажу очень спорную мысль – ни одна другая компания так бы не поступила. Но Intel, безусловно, уникален в своей вере.
Поначалу Atom достиг определенного успеха в сегменте нетбуков и неттопов. Тут надо понимать, что Intel все еще играл на своем поле – батарейки у этих устройств мощнее, чем у телефона, а стандартной операционкой является Windows co всем набором классического x86 софта. А вот дальнейшее «наступление» в область смартфонов и планшетов успеха не имело. Экосистема уже полностью сложилась вокруг ARM, и даже трюк Houdini – бинарный транслятор ARM > x86 – не спас положения.
Но главная беда даже не в этом. Дело в том, что мобильные процессоры – это с необходимостью System on Chip[23] (SoC). По сути, не так важно, какое ядро тащит операционную систему: ARM или Atom – Android неплохо оптимизирован под оба. Важно то, что большинство стандартных функций – поддержка wireless[24], медиа-кодеки, шифрование/дешифрование – выполняются на отдельных IP-блоках. Мне довелось попасть на «разбор полетов» (вроде бы он тоже был на ISA CPT) по поводу этих функций. И там все говорили одно и то же – здесь конкуренты сделали на доллар дешевле, здесь на полватта эффективнее и т. п. Что совершенно неудивительно – пока мы решали вопрос религиозной чистоты, потом восстанавливали легкомысленно потерянную экспертизу, потом заново выстраивали экосистему, наши конкуренты занимались оптимизацией. Так что, как и в случае с Xeon Phi, к неудачам Intel в мобильном сегменте ISA как таковая не имеет особого отношения. Просто мы упустили время, которое потом не смогли наверстать…
Индульгенция
Мне не сосчитать различных ISA, которые нашли свой конец в Intel, не выдержав противостояния с х86. Впрочем, есть одно исключение – встроенной интеловской графике всегда позволялось иметь instructions set[25], отличный от ортодоксального. Как будто она получила некую «папскую грамоту» которая хранила ее в самые темные времена костров инквизиции. Что можно объяснить бизнесовыми причинами, но все равно немного удивительно. Но тем не менее интеловская графика продолжает жить с начала 2000-х как независимая программируемая структура. Так, глядишь, и саму x86 переживет.
Варфоломеевская ночь
Ну и, конечно, мой рассказ об истории архитектуры был бы неполным, если не упомянуть о драматических столкновениях различных религиозных течений. Вообще, история развивалась циклически – вначале «еретические» архитектуры плодились (хотя бы в виде экспериментальных проектов), и потом «консерваторы» собирались с силами и брали «кровавый реванш». Я расскажу об одном случае 2013 года, когда «ортодоксы» Per Hammarlund и Bryant «Большой Полосатый Мух» Bigbee в один день «похоронили» проекты «вольнодумцев» VIP Бориса Бабаяна и Moonrun Дейва Дитцела (ex-Transmeta). Я тогда сумел просочиться на ISA CPT в день postmortem[26]. Арташесович отстрелялся минут за десять. Во-первых, он был расстроен. Во-вторых, длинные речи на английском ему не очень даются. Зато Дитцел выдал настоящее шоу. Там было все – картинки, жесты, эмоции и очень много стоящих мыслей. Наконец спустя полтора часа Дейв открыл свой последний слайд «New Architectural Ideas at Intel[27]». Слайд был пустой. В гробовой тишине заседание закончилось. Занятно, однако, что из четырех упомянутых мной Intel Fellow[28] дольше всех продержался в конторе именно Бабаян (aж до декабря 2021-го). Дитцел отвалил практически сразу после описанных событий и создал свою фирму Esperanto Technologies. Hammarlund ушел в Apple в начале 2015-го. Bigbee продержался немногим дольше…
Но мне особенно врезалось в память, как примерно спустя год после Варфоломеевской ночи на ISA CPT кто-то вдруг задал риторический вопрос:
– А помните тех, которых мы сожгли на костре в прошлый раз? Возможно, они были не так уж и неправы…
Кризис среднего возраста
Продолжаем сагу под названием Made at Intel. Сегодня я хочу посмотреть на историю развития IT-компаний скорее глазами финансиста (есть у меня такая слабость), а не инженера. И провести некоторые параллели между жизнью корпораций и жизнью обычных людей.
Корпорации как люди
«Корпорации не существуют ради людей. Они не существуют ради великих идей. Они существуют исключительно ради денег». Я любил так говорить, объясняя какой-нибудь очередной затейливый поворот истории Intel. Действительно, далеко не все решения поддаются объяснению с чисто технологической точки зрения. Соображения бизнеса играют не меньшую роль. Также надо принимать во внимание внутреннюю политику, оргструктуру и массу других факторов. Корпорация напоминает живой организм со своей внутренней логикой, зачастую противоречивой. Сегодня может быть так, а завтра по-другому. Наблюдая за развитием ведущих мировых IT-компаний в течение примерно четверти века, я пришел к выводу, что между корпорациями и людьми можно провести некоторые аналогии. Сегодня я попытаюсь проиллюстрировать эту мысль, сравнивая Intel c такими IT-гигантами, как IBM, Microsoft, Apple и Huawei. Как и люди, компании обладают своим «темпераментом» (о котором можно судить, например, по волатильности курса акций) «характером», «возрастом»… Даже от места «рождения» кое-что зависит. Ну вот, например, IВM – корпорация восточного побережья США. С глубокой иерархией, склонностью к дипломатии и близким к европейскому менталитетом. В то время как Intel (да, наверно, и Microsoft) – типичные компании «дикого Запада», в методах себя особенно не стесняющие. Однако сегодня я бы хотел сосредоточиться на том, как меняются корпорации с течением времени. Как они проходят периоды роста, расцвета, зрелости и… перерождения (хотя и не все).
Юнцы, мужи и «ветеран»
Разумеется, «молодость», когда компания из стартапа превращается в IT-монстра, безусловно, интересна. Но коль скоро мы интересуемся лидерами рынка, начальный период можно охарактеризовать короткой фразой Юлия Цезаря: «Пришел, увидел, победил». Разумеется, его проходят единицы из тысяч. Но, как правило, начальный период – это поглощение доли рынка, либо существующего, либо вновь созданного и растущего. Как правило, в этот момент «у руля» компании находятся «творцы» – инженеры, создающие конкурентное преимущество, и предприниматели, обеспечивающие экспансию на рынке. Доходы и (или) капитализация прибывают по экспоненте. Деревья кажутся растущими до небес, а небеса – бесконечно высокими. Такой вот сценарий успешной юности. И с изрядной долей произвола к таким молодым (или входящим в раннюю стадию зрелости) компаниям я отнесу Google (основан в 1998-м), Amazon (1994), Facebook (2004) и Netflix (1997).
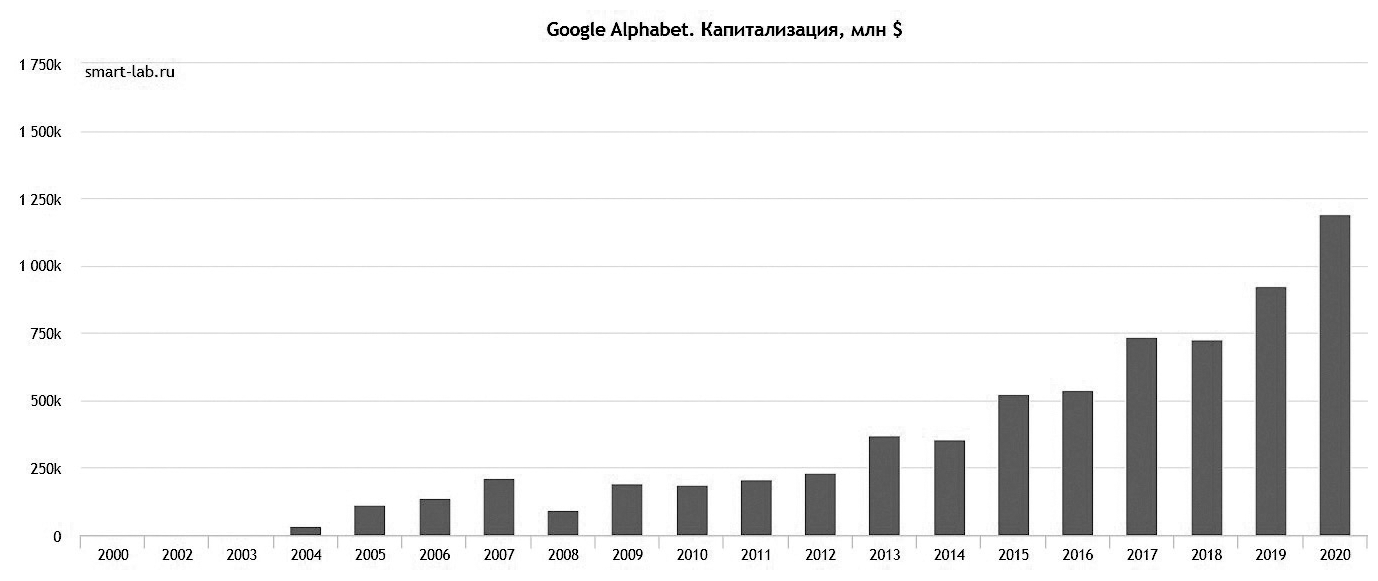
Но вот потенциал роста исчерпан, и компания сталкивается с новыми для себя проблемами. Они требуют нового подхода и зачастую приводят к изменению структуры и самого духа корпорации. Поэтому с исторической точки зрения более занимательны компании постарше. Наиболее почтенной IT-компанией с точки зрения возраста является IBM. Корни ее уходят еще в XIX век, но само название IBM появилось в 1924 году – то есть почти 100 лет назад. В своей истории IBM прошла через несчетное число кризисов и перерождений, вполне пройдя «проверку на прочность». Intel (1968) и Microsoft (1976) я отнесу к корпорациям зрелого возраста, и многое из того, что произошло с ними, можно понять, изучив историю IBM. Аpple (1976) хоть и является почти «ровесником» Microsoft, стоит все же несколько особняком. Дело в том, что история Apple долгое время была неразрывно связана с одним человеком. С такой неординарной личностью, как Steve Jobs – человеком, всегда стремившимся к вершине и сумевшим ее достичь (пусть и не с первой попытки).
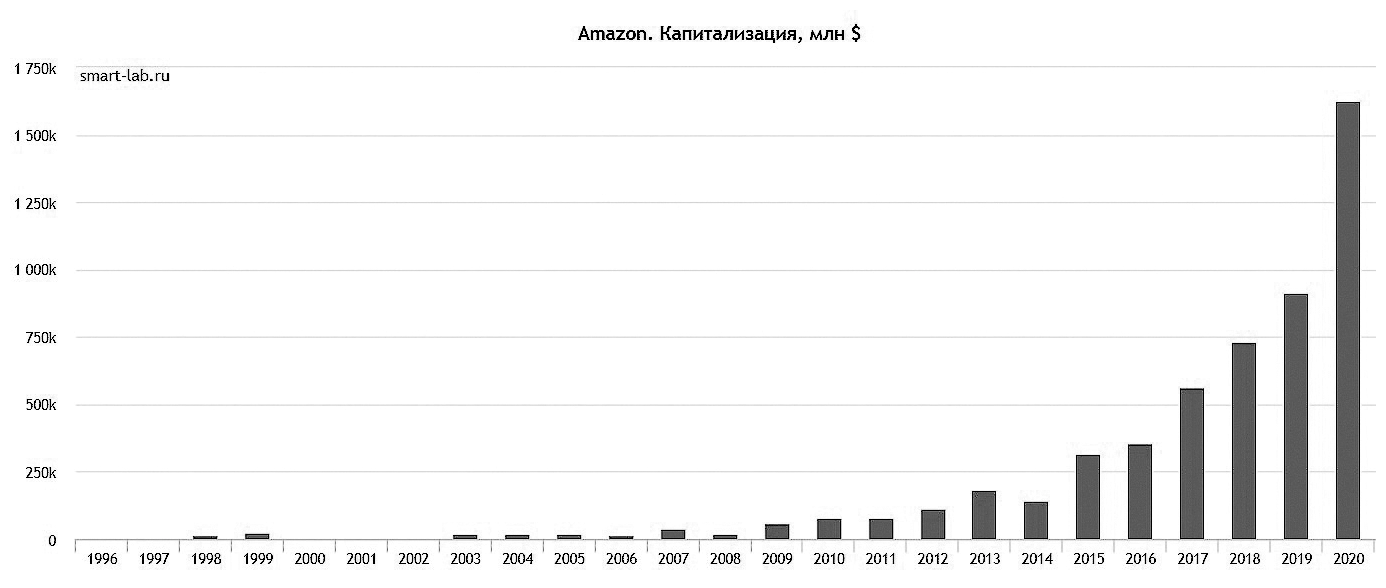
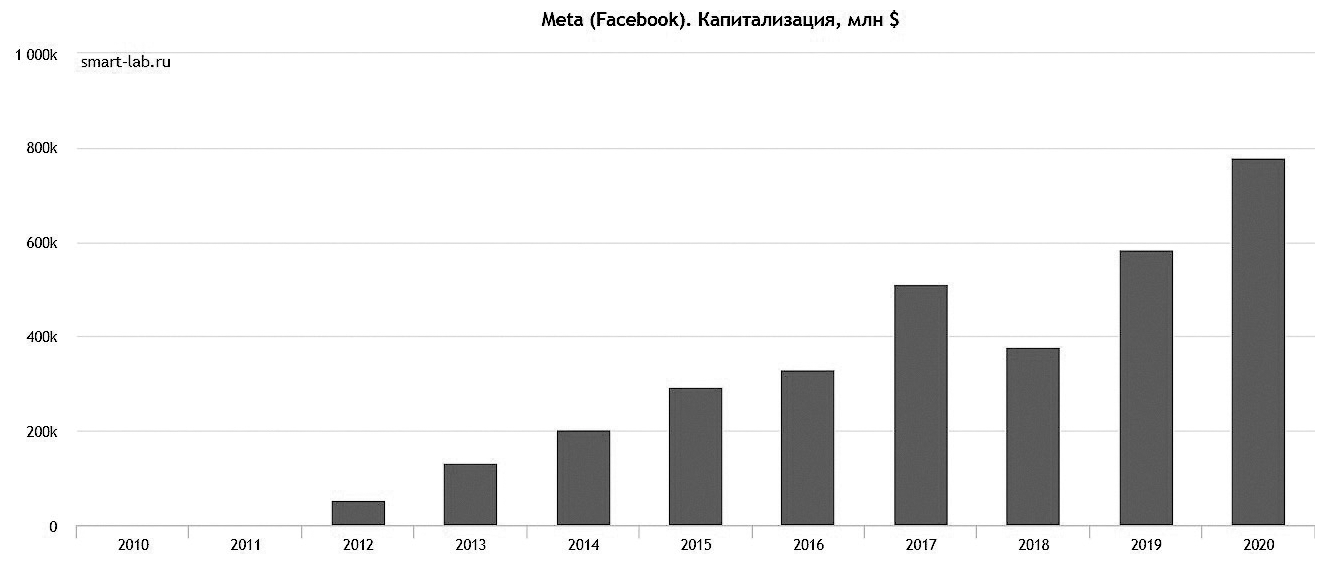

Кризис среднего возраста
Так что же происходит с компаниями, когда иссякает первичный импульс? Понять это можно по аналогии с «кризисом среднего возраста», так или иначе посещающим большинство людей в районе сорока лет (плюс-минус). Это когда все «генетически запрограммированные» цели (прибыль, IPO, лидерство в определенном сегменте рынка) достигнуты, а новые еще не созрели. Когда лидеры, тащившие компанию на своих плечах много лет, пресыщаются успехом или просто устают. Когда становится понятно, что до небес деревья все-таки не растут. Идеалы юности размываются, а заменить их нечем. И в подавляющем большинстве случаев на первый план выходит зарабатывание денег. Компании выучиваются идеально контролировать свои финансовые показатели – норму прибыли, расходы на RND и даже курс собственных акций. Безусловно, financials[29] являются самым понятным из всех ориентиров, только вот… Почему-то IT-компании не могут жить так же, как McDonalds и Coca-Cola, не могут быть просто «машинами по зарабатыванию денег». И постановка financials во главу угла зачастую ведет их в тупик.
История знает массу примеров кризисов подобного типа. В конце 80-х – начале 90-х годов прошлого века, когда я только начинал знакомиться с азами программирования, безусловным лидером на рынке была корпорация IBM. Мы тогда учились на технике из соцлагеря – болгарских машинах «Правец» или восточногерманских Robotron. (Я даже писал что-то на тамошнем ассемблере, но сейчас, хоть убей, не вспомню, как он выглядит.) Но каждый мальчишка втайне мечтал об IBM PC. Именно IBM определила концепцию персональных компьютеров и захватила львиную долю их рынка. Будущее представлялось безоблачным, а место на вершине незыблемым. Но высокотехнологичный рынок никому не дает долго почивать на лаврах. Кризис, как всегда, подкрался незаметно. Intel и Microsoft, которые рассматривались как «cубподрядчики», производящие процессоры и операционные системы для персональных компьютеров, постепенно оттеснили IBM c ведущих позиций. Так образовался тандем Wintel, который оставался на вершине в течение следующего десятилетия. А IBM погрузился в «кризис среднего возраста» c его экзистенциальными вопросами и мучительными поисками себя.
В поисках «Новых сущностей»
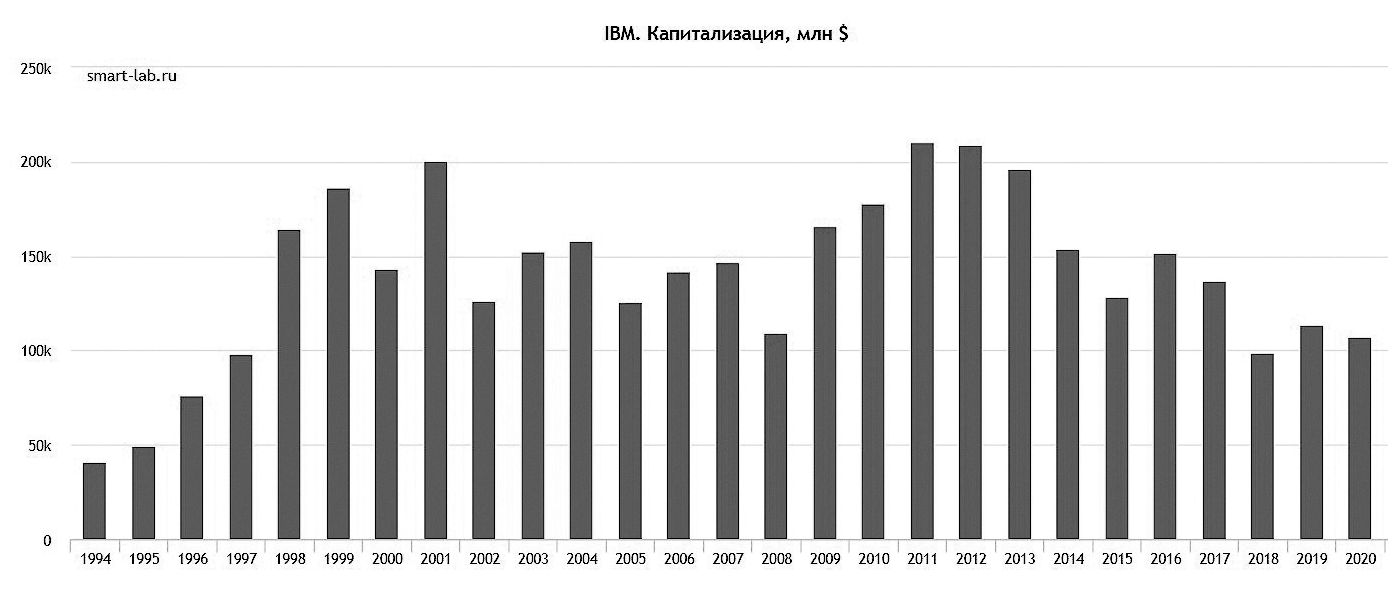
Преодоление «кризиса среднего возраста» – задача непростая, и справляются с ней отнюдь не все. Отчасти опасность состоит в том, что его нелегко распознать. Финансовые показатели остаются стабильными или даже растущими, но исчезает тот «дух авантюризма», который был присущ компании во время восхождения на вершину. И для того чтобы его возродить, нужна какая-то новая идея. Идея, которая приведет к «перерождению» компании, вдохнет в нее новую жизнь. Для IBM такой идеей стал уход от чисто «железного» бизнеса в сторону сервисов и консалтинга. Потеряв лидерство на рынке PC в 90-х, IBM оказался всего лишь «одним из» многочисленных OEM. Но великие компании отличает то, что они не довольствуются вторыми ролями, а ищут новые пути на вершину. И такой путь нашелся. Далеко не сразу, и я даже не уверен, что IBM так все и задумывал. Однако в 2002 году корпорация приобрела консалтинговое подразделение Pricewaterhouse Coopers, и с этого момента началось «перерождение» компании. Дальнейшие приобретения IBM все больше тяготели к сфере сервисов. А от «металлолома» корпорация избавилась, продав сначала клиентский, а затем и серверный бизнес Lenovo. В данный момент более половины доходов IBM обеспечиваются сервисами и консалтингом. И рынок (самый суровый критик инженерного гения) вполне приветствовал подобное перерождение компании. В середине 2000-х акции IBM демонстрировали устойчивый рост.
Другой яркий пример «перерождения» – это, безусловно, Apple. C момента основания корпорации основной бизнес ее был связан с выпуском PC Macintosh. И в конце 90-х он зашел в тупик – годовые убытки корпорации достигли двух миллиардов долларов. Однако вернувшийся на должность CEO в 1997 году Steve Jobs (в 42 года!) сумел исправить положение. Он одним из первых осознал огромное будущее мобильной электроники и ее тесную связь с облачными сервисами. iPod, iPhone и iCloud ознаменовали «перерождение» Apple и вывели компанию в мировые лидеры с точки зрения рыночной капитализации.
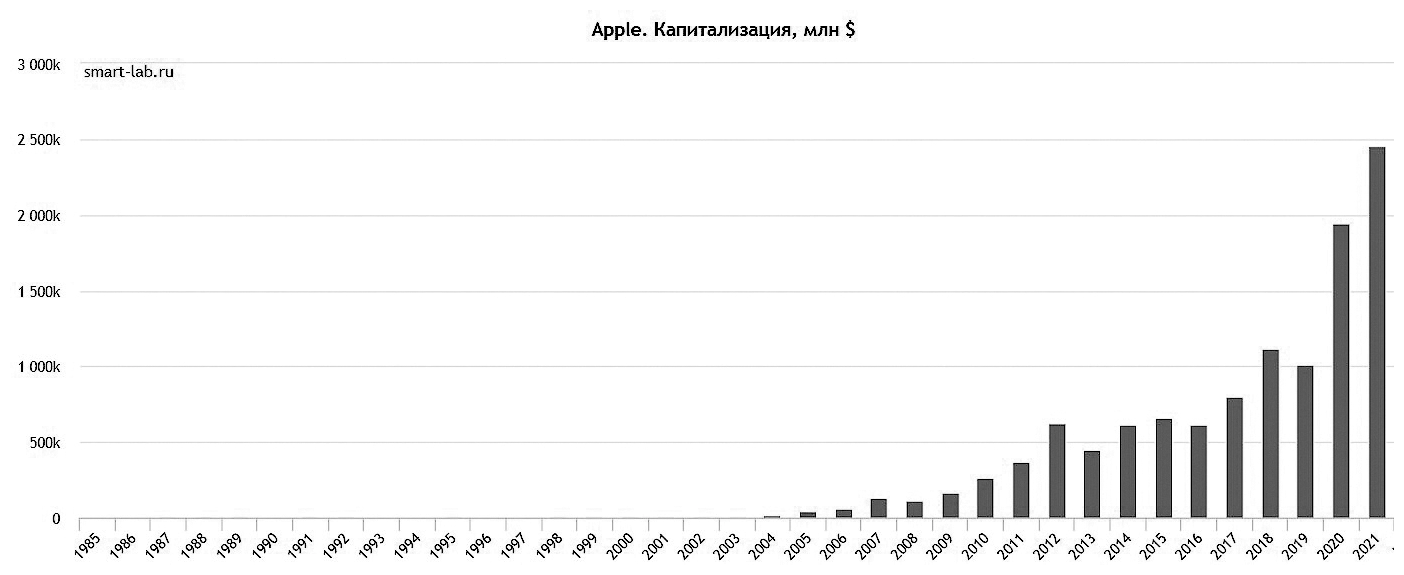
Давайте еще посмотрим на графики капитализации. Следующая картинка показывает, что Microsoft также успешно справилась с кризисом среднего возраста.
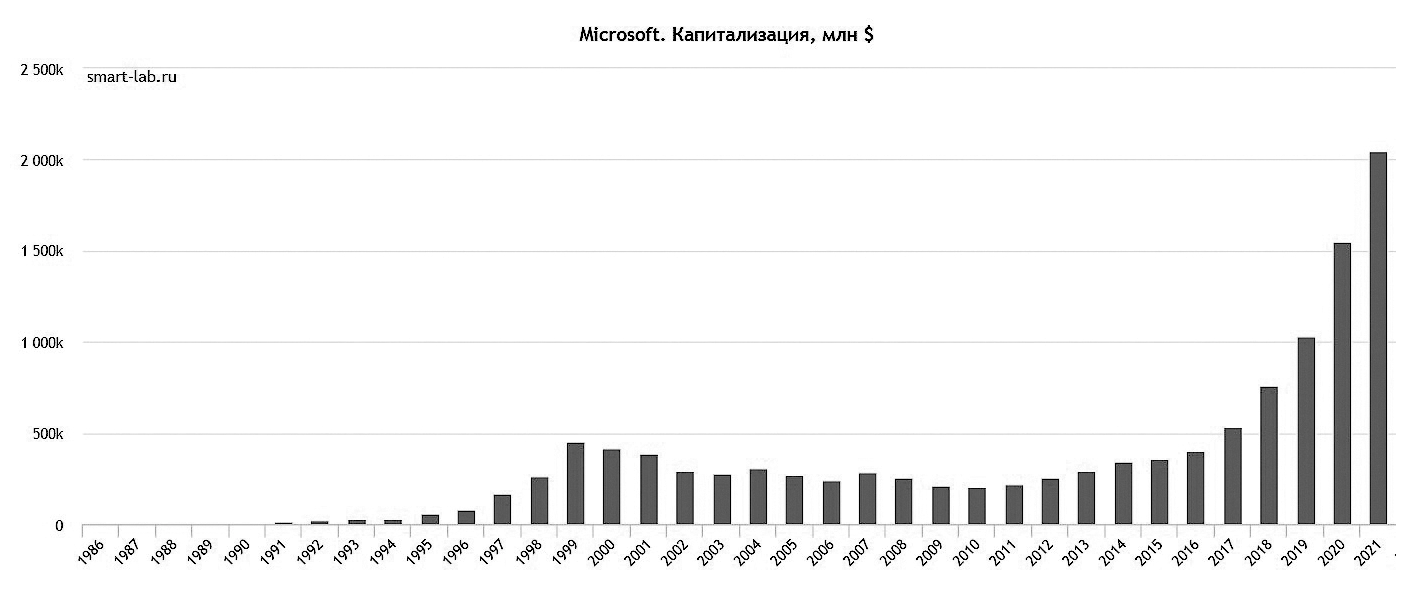
Драйвером трансформации компании (с определенной долей произвола) назову Microsoft Azure. Если еще 10 лет назад Microsoft однозначно ассоциировался с OS Windows, то сейчас около половины доходов приносит облачный бизнес. Впрочем, XBox и «новоприобретенный» (2016) LinkedIn также чувствуют себя неплохо.
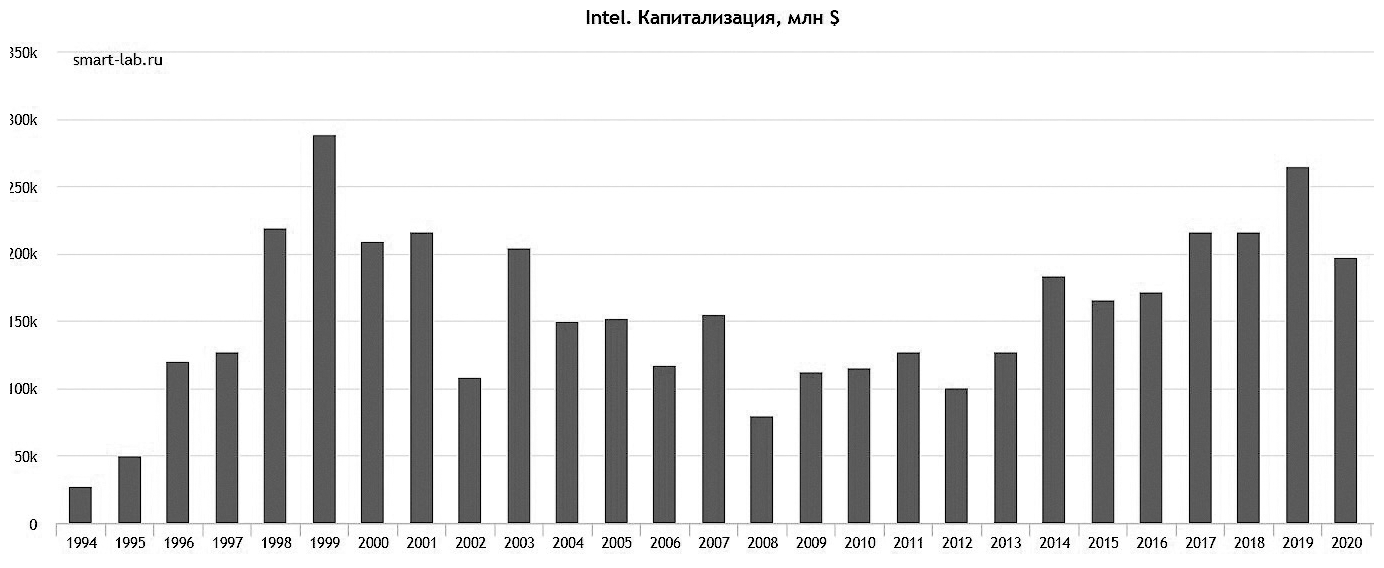
А вот взгляд на капитализацию Intel говорит нам о том, что «кризис среднего возраста» в компании затянулся.
Несмотря на многочисленные попытки найти новое Identity[30], Intel по сути так и остался исключительно производителем процессоров. Безусловно, это отличная ниша, и спрос на продукцию с каждым годом растет. Но вот по капитализации MSFT уже превосходит INTC более чем в 10 раз, а ведь когда-то они были почти одинаковы… В качестве причины многочисленных провалов попыток трансформации я уже приводил «религиозность». Также стоит упомянуть очень комфортную позицию на основном рынке – конкуренция со стороны AMD долгие годы носила «эпизодический характер». Ниже разберу еще пару препятствий, вставших на пути перемен.
«Лебединая песня»
Еще одним характерным признаком «кризиса среднего возраста» является то, что «творцов» на первых ролях в компании сменяют «бухгалтеры». Они не меньше, чем инженеры, желают своей корпорации процветания. Только представляют его по-своему. В их понимании высшая эстетика состоит в оптимизации примерно такого вида таблички.