Последний отзыв

Книга дельная. Без воды, приводятся реальные кейсы и способы их разрешения. Много практичных полезных советов и методик. Кое-что уже испробовала в дел...
Далее
По всем вопросам обращайтесь на: info@litportal.ru
(©) 2003-2025.
✖



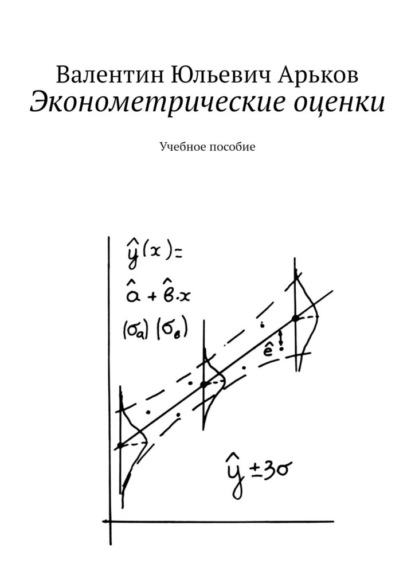
Эконометрические оценки. Учебное пособие
Настройки чтения
Размер шрифта
Высота строк
Поля
Итак, мы запускаем Colab. Нас спрашивают, хотим ли мы открыть существующий файл или создать новый. Создаем новый блокнот.
Вводим первую команду, нажимаем комбинацию клавиш [Shift+Enter]. Проходит некоторое время на запуск – в правой верхней части экрана выводится сообщение про соединение с виртуальной машиной: Connect.
Обратим внимание, что при вводе функцию сразу появляется всплывающая подсказка.
Когда ячейка выполнилась, слева от этой ячейки блокнота видим комментарий в квадратных скобках – выводится какое-то число. Это порядковый номер выполненной ячейки. Ячейки можно запускать в разном порядке, и это будет отображаться в квадратных скобках.
И ещё один момент: при вычислении среднего значения не уточняется метод расчёта. В описании функции говорится: arithmetic mean, то есть среднее арифметическое. На занятиях по статистике вы можете узнать, что среднее можно считать десятью разными способами. Но средняя арифметическая простая используется чаще всего.
Чтобы вывести полученную оценку на экран мы просто вводим имя переменной.
Запускаем несколько раз: Runtime – Run All.
Для вывода на экран можно также использовать команду print. Это обеспечит побольше знаков после запятой. Здесь можно задать любой формат вывода.
Подведём итоги. Неважно, какими средствами анализа мы пользуемся. Результаты обработки данных каждый раз представляют собой случайные числа. Они будут приближаться к точному, правильному значению. Но оценка содержит внутри себя случайность.
Ваша задача – потренироваться и убедиться в следующем. Оценки – это результат обработки реальных данных. Исходные данные содержат случайность. Поэтому оценки тоже являются случайными числами. Нужно проделать этот опыт на локальном компьютере и в облаке, см. рис.
Рис. План задания
4. Распределение
Наша следующая тема – распределение. А точнее, распределение вероятностей. Это понятие из теории вероятностей.
Чтобы всё запутать, у нас есть ещё одно понятие распределения – в экономике. Это касается дистрибуции, когда оптом берут крупную партию товара и развозят по магазинам мелкими партиями. Конечно, это не имеет никакого отношения к распределению в статистике.
Нас будет интересовать статистика, эконометрика, теория вероятности. Здесь распределение – это зависимость, показанная на рис.
Рис. Примеры стандартных распределений
Итак, распределение – это вероятность появления разных значений какой-то случайной величины. На рисунке приведены два примера – равномерное и нормальное распределение. Мы их подробно исследовали на лабораторных работах по статистике.
При использовании программного генератора достаточно указать название распределения и его параметры.
Нормальное распределение имеет один пик. В целом, такая форма кривой называется колоколообразной. То есть она похожа по форме на колокол.
Соответствующее английское название – Probability Distribution. Probability – это вероятность. Distribution – распределение.
Распределение вероятностей – это вероятность появления разных значений случайной величины. Когда мы обрабатываем реальные данные, эту вероятность мы можем найти только приблизительно с помощью оценок. На практике распределение – это частота появления разных значений. Что-то бывает чаще, что-то бывает реже.
Чтобы сгенерировать случайные числа, мы используем программный генератор.
Рис. Запуск генератора
Всё начинается с равномерного распределения. Случайное число от нуля до единицы. Это считается своеобразным стандартом, строительным «кирпичиком» для реализации любого другого распределения.
Рис. Стандартное нормальное распределение
В некоторых случаях мы можем вручную указать тот диапазон значений, который нас интересует. Стандартные параметры – это диапазон значений от нуля до единицы.
Рис. Настройка генератора
Запускаем генератор случайных чисел. В диалоговом окне указываем число переменных, см. рис. Напомним, что переменные в электронных таблицах и во многих других случаях располагаются по столбцам. Это имеет отношение к истории. Традиционно, задолго до появления компьютеров числа записывали в колонку. Внизу столбца подсчитать сумму. Вручную числа удобно складывать столбиком. Соответственно, и в компьютерах используется традиционное расположение данных. Оно интуитивно понятно.
Это касается электронных таблиц, баз данных, обработки данных в Python. И это касается настройки генератора случайных чисел. Количество случайных значений задаётся как количество строк. Количество переменных – это число столбцов.
Далее указываем форму распределения – равномерное.
Параметры равномерного распределения – минимальное и максимальное значения. По умолчанию от нуля до единицы.
Начальное значение генератора: 1234.
Диапазон ячеек для вывода.
Рис. Вставка гистограммы как статистической диаграммы
Чтобы рассмотреть полученное распределение, используем график под названием гистограмма.
Мы рассматриваем пример в Excel.
Выделяем диапазон ячеек. Вызываем вставку гистограммы, см. рис.
В меню Insert – Chart есть две похожие кнопки: Bar Chart и Histogram.
Bar Chart – это простая столбиковая диаграмма, причём для каждого значения входного диапазона строится свой отдельный столбик. В некоторых вариантах перевода эта кнопка обозначена как «Гистограмма». Конечно, это запутывает пользователей. Если построить столбиковую диаграмму по 10000 значений, мы получим 10000 столбиков. Можете попробовать – чтобы больше не «попадаться».
Histogram – это гистограмма, то есть столбиковая диаграмма частот. Частоты считают для сгруппированных данных. Это частота попадания чисел в интервалы (диапазоны значений), см. рис.
Рис. Меню Вставка – Диаграмма
Этот новый инструмент – «Гистограмма как статистическая диаграмма» – работает только в последней версии Excel. Поэтому рекомендуем при возможности обновить версию MS Office.
Построим гистограмму и посмотрим, чем она отличается от других графиков. Всплывающая подсказка сообщает, что этот график позволяет изучить распределение данных, сгруппированных по интервалам значений. В английском варианте интервал группировки называется bin. Буквально слово bin означает «корзина». Иногда его переводят словом «карман». Более грамотно было бы назвать его «интервал группировки данных».
Таким образом, наши данные – от нуля до единицы – сгруппированы по нескольким интервалам. Excel сам автоматически подсчитывает, сколько чисел в какой интервал попадает. Затем строится столбиковый график полученных частот. Так что это особый график со встроенной автоматической обработкой данных.
Рис. Гистограмма с автоматическими настройками
Мы получаем график распределения – «автоматическую гистограмму». В теории все столбики для гистограммы равномерного распределения должны быть одной высоты. Гистограмма по ограниченному набору данных не идеальная. Высота каждого столбика – частота – содержит в себе случайность, небольшую случайную ошибку.
Внизу, в качестве подписи под столбиками указаны те самые интервалы группирования данных. Нижняя граница обозначена круглой скобкой – не включается в расчёты. Верхняя граница – квадратная скобка – включается. Таки образом, число на границе будет относиться к нижнему интервалу. Что, ка и почему здесь происходит – более подробно обсуждается в курсе «Статистика».
Рис. Происхождение слова «Гистограмма»
Само слово «гистограмма» буквально означает «столбиковая диаграмма», то есть «график в виде столбиков». Первая часть – histo – означает «столбик», вторая часть – gram – «график, диаграмма».
Наши столбики изображают частоту появления разных значений случайной величины. Напомним, что частота примерно соответствует вероятности.
Другие электронные книги автора Валентин Юльевич Арьков





Последний отзыв
Книга дельная. Без воды, приводятся реальные кейсы и способы их разрешения. Много практичных полезных советов и методик. Кое-что уже испробовала в дел...
Далее